ImSeoArchive RegEx Grabber can scrape data in a few time.
It works fetching webpages that you can load by a simple txt file and selecting what scrape from built-in regex library.
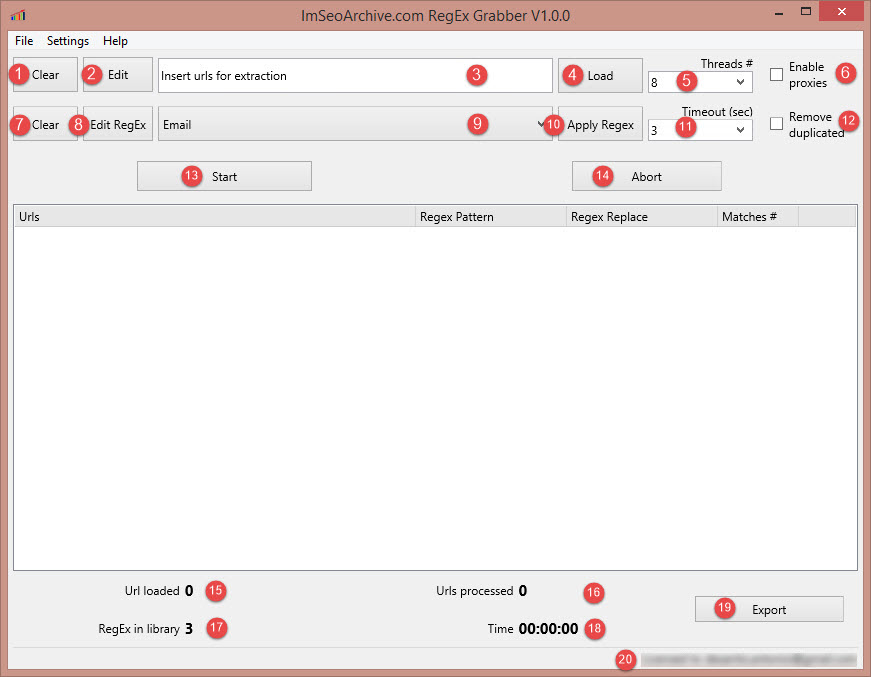
In the image below there is the main GUI, following a brief description of every button:
1.Clear: clean your sites list (Point 3)
2.Edit: Open a text editor to edit urls list used to scrape data.
3.File path urls: File path containing your urls list used to scrape data .
4.Load: Open a window for selecting file containing urls list used to scrape data. After the file is opened its path will appear in point 3 textfield.
5.Threads #: Choose the thread number you want to use. If you have a slow internet connection I don’t suggest to growth this value. Threads number increment changes according your CPU detected on your machine. For example if you have a PC/Mac equipped with dual core CPU the number increment will 2, 4 for quad core CPUs, etc.
6.Enable proxies: enabling proxies you can hide your ip so you can fetch webpages anonymously.
7.Clear: Reset to first index drowdown menu at point 9.
8.Edit RegEx: Open a windows to edit regular expressions.
9.Drowdown menu: select what you want extract from webpages
10.Apply Regex: set a regular expression in column "Regex Pattern"
11.Timeout (sec): you can set timeout of connection. This value can be changed according time that you think will be necessary to respond to your pinging.
12.Remove duplicated: remove duplicate matches.
13.Start: start the extraction process
14.Abort: abort extraction process. This button is enabled when extraction process is in progress.
15.Url loaded: indicate the number of websites you load when you click on button “Load” (Point 4)
16.Url processed: it indicates the number of urls processed during the extraction process. Remember that at the end of extraction process this number is equal to Url loaded (point 15)
17.Regex in library: it indicates the number of records of regex library. This number will change if you add or remove entries in RegEx library clicking on "Edit RegEx" button
18.Time: it represents the time elapsed since you press the start button
19.Export: At the end of extraction process you can export results in a txt file.
20.License: It indicates the email linked to your license.